Messaging technologies showdown - scaling clients
·The term messaging has become as ambiguous as service. There are many messaging technologies available and while they all provide publish-subscribe capabilities, there are many subtle differences across these technologies. One angle that I find helpful to differentiate these technologies, is by looking at how they support scaling clients (subscribers) up and down.
Logical and physical clients
At first glance, that sounds like a naive question; the publish-subscribe pattern is designed to make the publisher independent from the subscriber (and vice-versa), therefore scalability of subscribers should be one of the basic benefits of publish-subscribe messaging technologies. When referring to scaling up and down, we think about multiple physical instances of the same application (code), which I also refer to as the logical client. When looking at the published event, ask the following questions: Should all physical instances subscribed to the event receive the event or only one physical instance per logical client? The answer typically depends on the type of message that is being published (but this is a whole other topic).
Note: Scalability isn’t the only reason for having multiple client instances. When deploying new versions in an environment that supports zero-downtime deployments (e.g., Kubernetes), you’ll most likely encounter situations with multiple active client instances (running on different versions!).
Broadcasts
In basic publish-subscribe scenarios, every publisher (every physical instance) receives the published message. Let’s call this behavior broadcasts because I think this fits well with the analogy of radio broadcasting where just every receiver can pick up the signal (message) completely independently from every other receiver.
MQTT is one of the most prominent examples of a simple, lightweight publish-subscribe protocol. MQTT clients can only subscribe to topics, and there is no concept of message queues exposed in the protocol. Every client that subscribes to a topic receives a copy of the message.
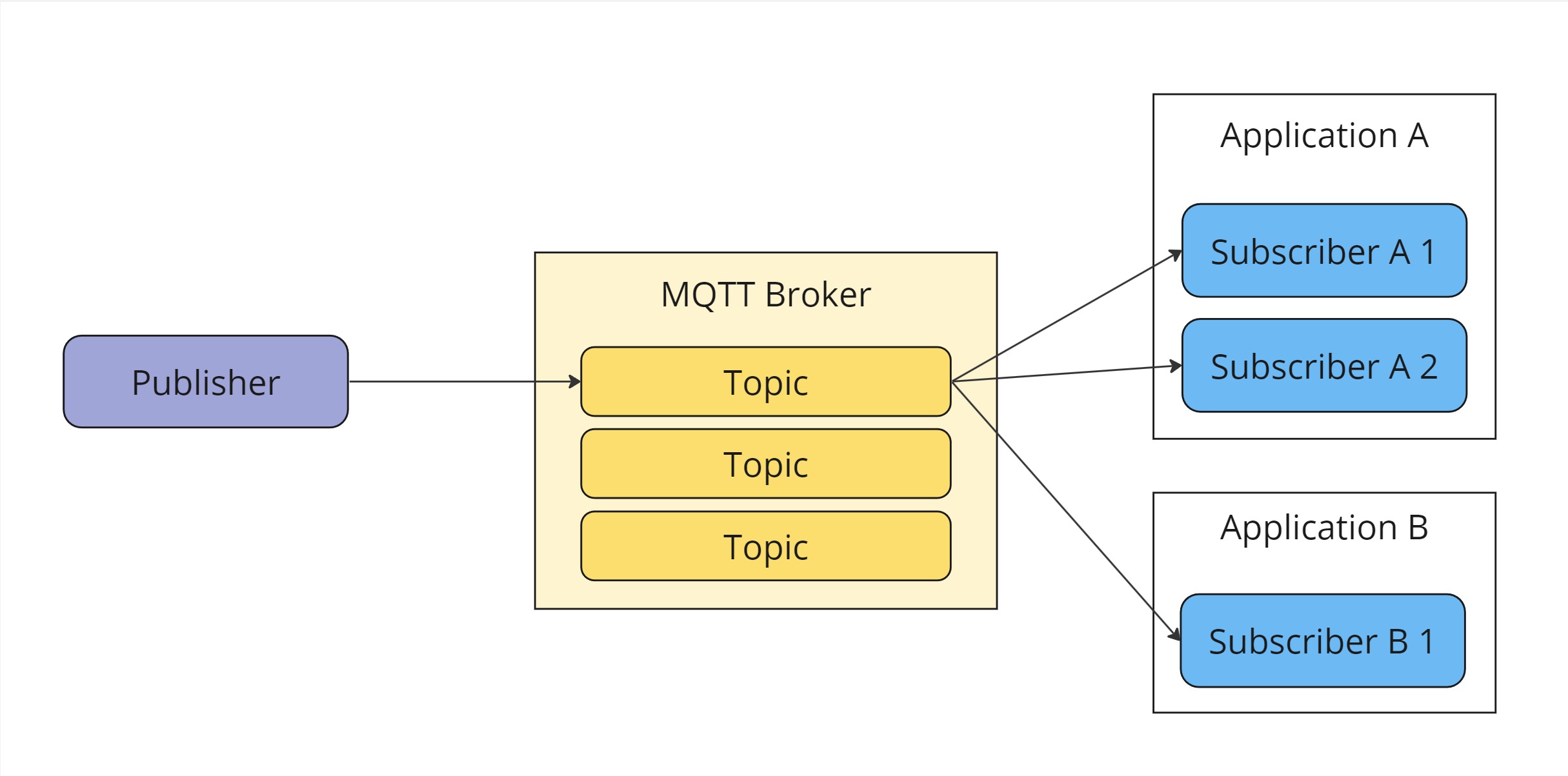 This diagram shows how each subscriber instance will receive a copy of a published message.
This diagram shows how each subscriber instance will receive a copy of a published message.
Typically, MQTT is used in IoT scenarios where the scaling aspect isn’t that important as physical devices don’t scale that often or unexpectedly. This broadcasting behavior is also helpful for continuous data streams (like telemetry data), where the broadcasting behavior is typically preferred. When you need to ensure that only one physical instance per application processes the event using MQTT, I can imagine the following solutions:
- With MQTT protocol version 5, MQTT introduced the concept of subscriber groups. Within a subscriber group, only one subscriber will receive the published message. Subscriber groups are a feature not supported by every MQTT broker. Subscriber groups are very similar to the competing consumer behavior.
- Have a single subscriber that forwards messages from MQTT to a message queue (e.g., using AMQP), where it will be consumed by the logical application as described in the next section.
- Use the inbox pattern to deduplicate the broadcasted message across the physical subscriber instances of an application.
Competing Consumers
Message queues are another concept many messaging technologies use. It extends the publish-subscribe model with an explicit entity, typically a queue, on the broker that multiple physical subscriber instances can share. While a published message is forwarded to all subscribed queues, there is only one queue per logical application. The queue allows many consumers to interact with it at the same time but ensures that a message is only accessible to a single consumer.
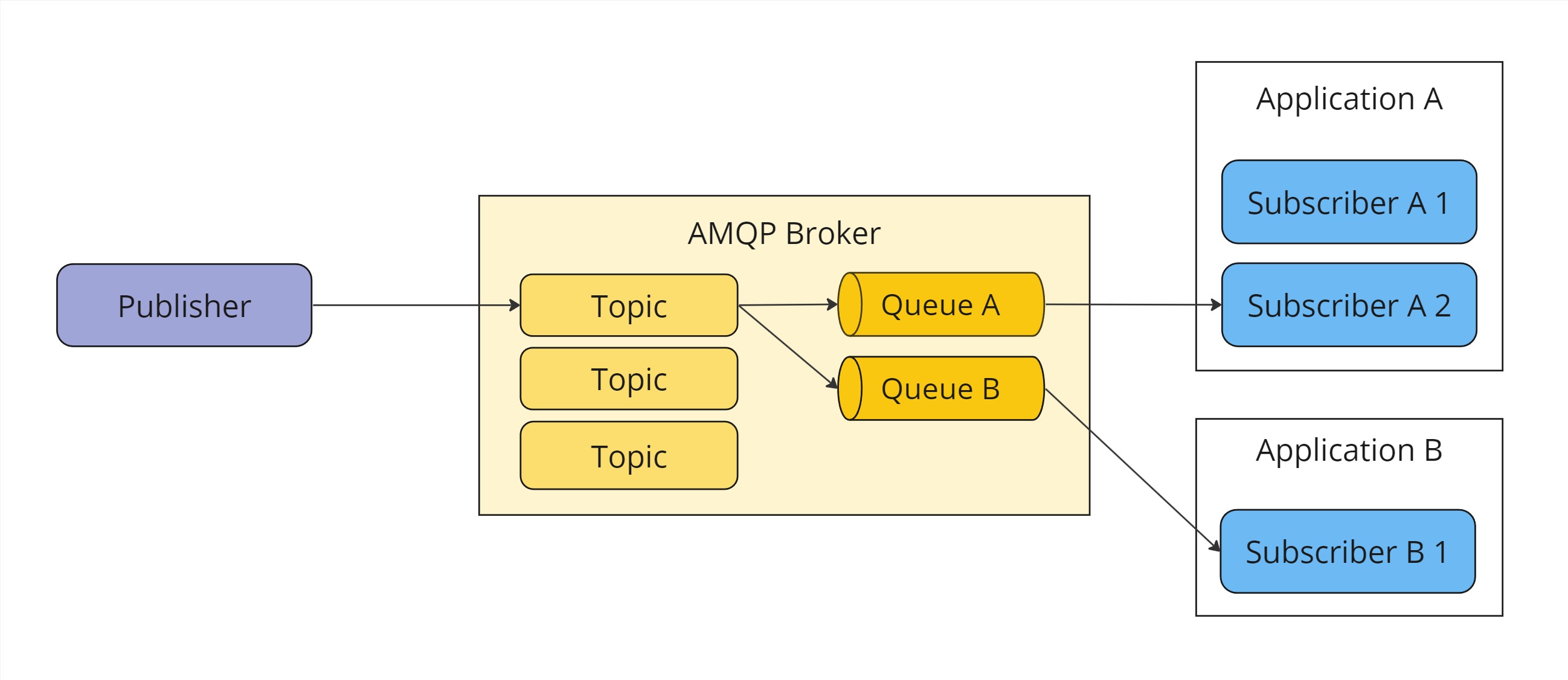 In this diagram, each logical application has its own message queue. Using the competing consumers model, exactly one client instance is able to consume a message per logical application.
In this diagram, each logical application has its own message queue. Using the competing consumers model, exactly one client instance is able to consume a message per logical application.
Queues make client scaling simple and very flexible, as clients can be scaled up or down at any point, and messages can be distributed easily across all active client instances. One downside of this approach is that it makes broadcasts more difficult. If all clients should receive some messages, each client requires an additional, dedicated queue.
Publish/Subscribe with logs
Event Stream Processing is another messaging approach that has gained much popularity. Kafka is the best-known example. AWS and Azure offer similar products as-a-service. I’m using Kafka as the technology name here; it’s so commonly used.
Kafka publishers store messages in a topic partition. Every topic has one or more partitions to persist messages. Subscribers can then read messages from a partition at any point without the message being removed. Kafka also defines the concept of client groups, which ultimately is the same as our logical client. Each client group can have multiple client instances that belong to the group.
In Kafka, a partition can only be read by one client instance within the same client group. This has several implications:
- Similar to “traditional” message queues, one event will be processed by a single client instance within the logical application.
- It’s harder to mix broadcast and competing consumer models at the same time because a client instance belongs to a single client group, and broadcasts effectively only work across client groups, not across client instances.
- The maximum number of client instances is limited by the number of partitions of a topic, as only one client instance can process a partition. This limits scalability (scaling up or down is also more complex as client instances need to be rebalanced across the partitions).
- Load balancing primarily depends on the partitioning strategy and the number of partitions. Over-simplified: Scaling subscriber instances is more difficult than using traditional message queuing technologies.
- Message processing happens sequentially. Unlike with message queues, it isn’t really possible to move individual messages independently. A single failing message can therefore block the entire partition from advancing. Guaranteed ordering (down to the client consumption) is one of the main benefits of Kafka but also one of the biggest limitations when it comes to using Kafka as a message broker.
- An additional difference of Kafka is that messages aren’t removed from the broker once a client has processed it. Therefore, clients can decide to re-process messages.
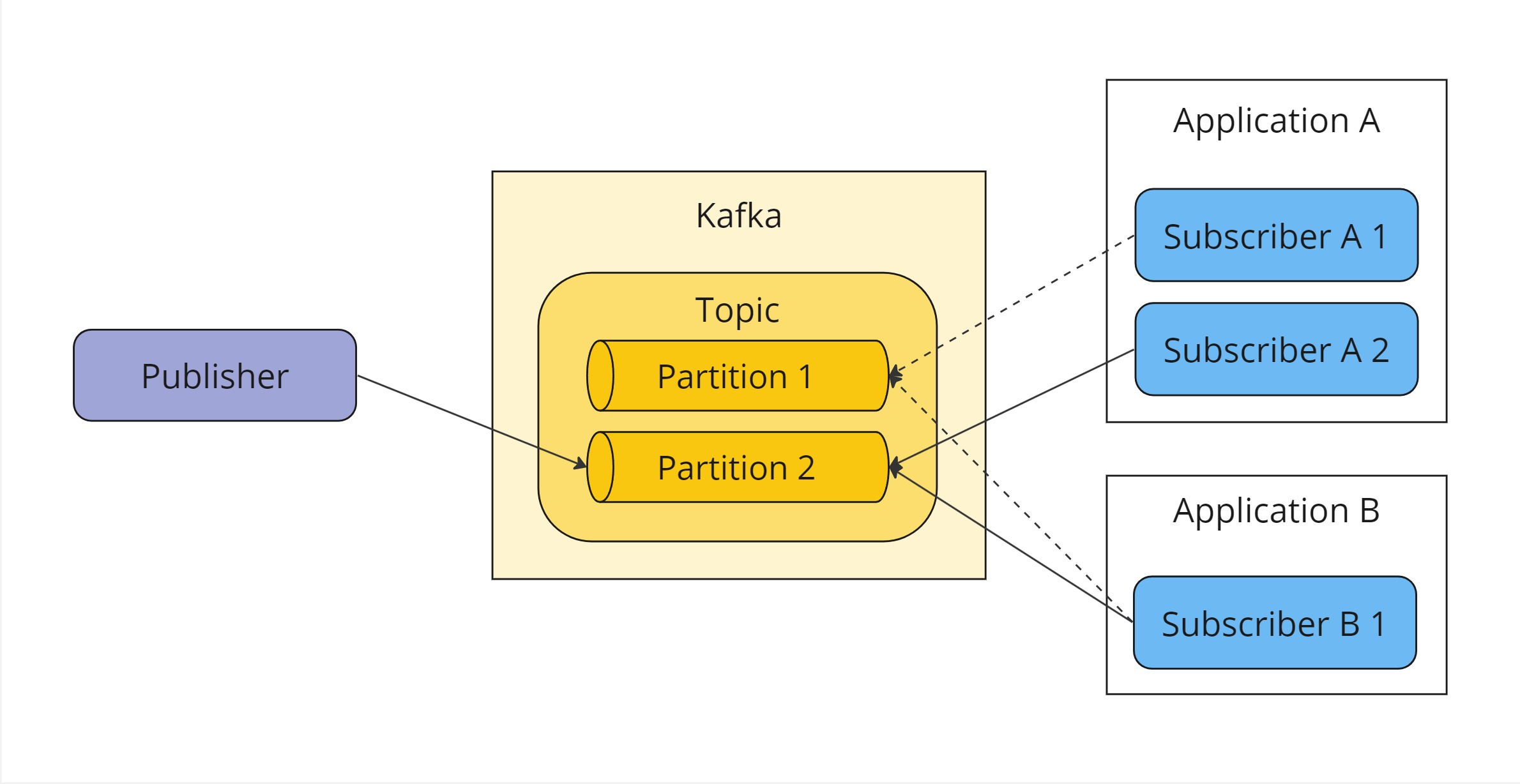 The diagram shows how each subscriber instance of a logical client is assigned to one more topic partition. A publisher publishes an event to a specific partition which will be read by one subscriber instance per logical application.
The diagram shows how each subscriber instance of a logical client is assigned to one more topic partition. A publisher publishes an event to a specific partition which will be read by one subscriber instance per logical application.
Conclusion
The competing-consumers model is often the most convenient and easy-to-use approach for most backend systems that consume discrete business-focused messages. Thinking about how the system behaves when scaling your logical applications can help you understand how different message technology choices will impact your system. Unless your messages are purely focused on data distribution, by default I’d recommend avoiding Kafka as a message broker, while it appears very similar from a distance, the little details are what’s going to cause you a lot of pain and require unnecessary complexity that other options handle much more easily.